Nvidia rules ML, not because its products are cost-effective

EDIT: I retract this post. I was fooled by NVidia’s tricky marketing, that listed only “sparse FLOPs” which are precisely twice the number of actual FLOPs. If we compare with this correction, AMD GPUs emerge as the clear winner in FLOPS/$ and memory/$.
Previous subtitle: “TPUs are very closed and expensive. AMD is like 2 years behind.”
Nvidia practically has a monopoly in ML training. Why has nobody broken it? Is it because of the ‘CUDA moat’, the fact that all ML software is already written for NVidia products? Is it because AMD drivers keep crashing? Because Huawei chips are only really available in China?
It is none of these things. Nvidia’s hardware is just the fastest, the most cost-effective, and all-around the best. Nobody has managed to outcompete them because it is hard, they make the best ML accelerators. I was surprised by this: I expected Google’s TPUs to be better and to only lose out because of the ecosystem, but this is not the case.
The latest Nvidia accelerator server, the B200, has the highest ExaFLOPS per dollar.1 Training is typically bottlenecked on FLOPS. Ergo, if you want your training to complete fast, you buy Nvidia.
The second most FLOPS-effective accelerator on my table is the flagship AMD MI355x at 56 EFLOPS/$, which was released in mid-2025. But close behind is the Nvidia H100, released in 2022, which will give you 52 EFLOPS/$ even now. Nvidia has enjoyed a sustained lead in FLOPS/$, and thus the correct choice for everyone training models is to buy Nvidia.

The other specs
This is sufficient to explain NVidia’s success. Really, I could end the blog post here. But there are more reasons that Nvidia is a better choice, and I must reach 500 words.
First, the other specs: it has plenty of memory. AMD nodes have more total memory and slightly more memory bandwidth. This matters if you are restricted to using a single node. This happens to academics and MATS scholars all over, because the open-source software that is available (Huggingface) has very bad support for training with multi-node. In that case, it can make the difference between being able to fit Llama-405B in your node, or not. (Such is the price of supporting ~all models, like Huggingface does.)
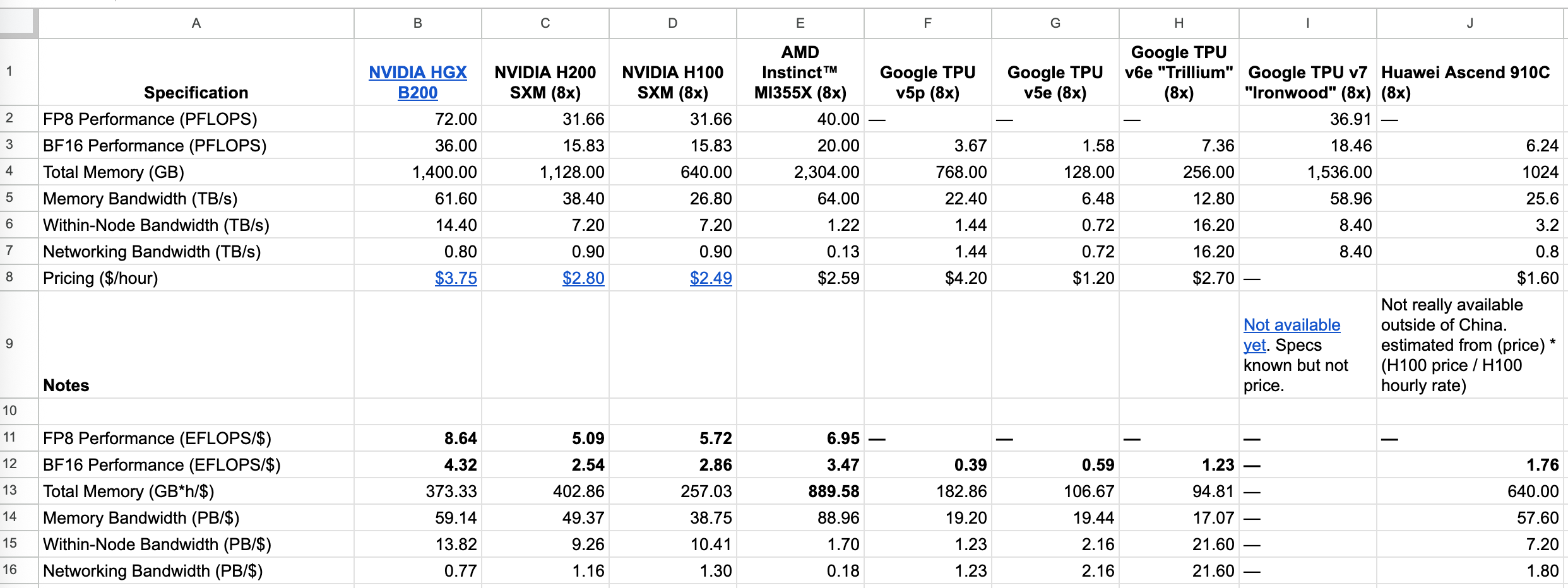
Second reason. TPUs don’t even support 8-bit floating point (FP8). Open-source training runs have moved to using FP8 over BF16 (Balanced 16-bit floats) since DeepSeekV3. Once the numerical issues were worked out, the advantage is enormous: it uses half the memory and you get double the FLOPS per second and dollar. (Also, TPUs have very few FLOPS per dollar).
Another issue with TPUs is the architecture and instruction set is private. This makes it harder to optimize the kernels as much as it is possible for nVidia GPUs. The lowest-level hardware access you can get, unless you partner with Google, is using Pallas (which is excellent for GPUs, so maybe that’s fine, but still).

Infiniband also rules
Nvidia nodes connect to each other with Infiniband, the original RDMA fabric with the most software. Nvidia bought Mellanox, maker of Infiniband, in 2020. Just before the huge model boom.
Because Infiniband has been around for a while, there are SSD storage devices that support communicating with it directly with very low latency and high bandwidth. This allows for clever hacks like Deepseek’s 3FS filesystem, which is fast enough to store the KV cache in SSDs during inference, effectively making it very easy to cache activations. During training, this makes it fast to save checkpoints.
In contrast, the machines which run TPUs have very little attached storage, only about 100GB. More storage is only accessible over the network at pretty terrible bandwidths. This forces lots of engineering to go into asynchronous checkpointing.
Conclusion
The latest, 2025-era AMD chips have slightly more FLOPS/s and FLOPS/$ than the H100, which is from 2022. TPUs are extremely expensive and outsiders to Google can’t even see the instruction set. The latest model, which hasn’t been released yet, is approaching AMD’s offering in total FLOPS and memory (and is thus only somewhat better than the 2022-era Nvidia H100).
Nvidia is beating everyone at the hardware AND the software. It’s not close.
I’ll be buying some more Nvidia stock after I post this. (This is a joke, not financial advice.)
See the table. We take the (PFLOPS/s) and divide by ($/h), and correcting by 3600s/h we get the numbers in the text.
Hey, great read as always. Your FLOPS/$ argument is so sharp. It realy makes you rethink the actual power of an entrenched ecosystem, doesn't it?